Analysis and Visualization of the IV 2004 Contest Dataset
Börner, Katy, Richard Klavans, Michael Patek, Angela Zoss, Joseph R. Biberstine, Robert Light, Vincent Larivière, and Kevin W. Boyack (2012) Design and Update of a Classification System: The UCSD Map of Science. PLoS ONE 7(7): e39464. doi:10.1371/journal.pone.0039464
Abstract:
The presented work aims to identify major papers and their interrelations, topic trends over time, as well as major authors and their evolving co-authorship networks in the IV Contest 2004 data set. Paper-citation, co-citation, word co-occurrence, burst analysis and co-author analysis were used to analyze the data set. The results are visually presented as graphs, static Pajek [1] visualizations and interactive network layouts. This webpage complements our two-page paper submission.
Team
This work was completed by the following team from the Indiana University School of Informatics and Computing:
- Weimao Ke
- Katy Börner
- Lalitha Viswanath
Tools
- As an initial step, we cleaned the data as described in the "Data Cleaning" section below.
- Microsoft Access, Microsoft Visual Basic, Microsoft DOM, Perl and Pajek too were used to analyze the dataset. Microsoft DOM and Microsoft Visual Basic were used to migrate the data from the given XML format into Access compatible format.
- Using Microsoft Access, queries were created to obtain different views of the dataset such as number of co-authors per author, number of papers per author, number of citations per author, etc.
- Pajek was used to visualize these results in a user-friendly and intuitive manner.
- Microsoft Excel was used to analyze and visualize the burst of words in the dataset. This burst analysis was performed using Kleinberg's Burst algorithm [2] provided as a part of the InfoVis CyberInfrastructure
Data Cleaning
Data cleaning comprised 80% of the time spent on this project. The data was converted into an MS-Access database provided below. Some results of the data cleaning are also shown below.
- Identifying Major Publication Venues (called sources) (314 unique sources originally provided ==> 106 unique sources after data cleaning)
- The source field was split with delimiter on ":" and extra spaces were trimmed.
- Records with identical source descriptions were mapped in Visual Basic.
- After sorting the records, additional source descriptions were mapped manually.
- Identifying Unique Keywords (1859 unique keywords originally provided ==> 1753 unique keywords after data cleaning)
- The table "keyword conversion" contains all 89 records of rules that were applied to identify a unique list of keywords.
- Identifying Unique Authors (1161 unique authors originally provided ==> 1036 unique authors after data cleaning)
- Duplicate author names were identified by trimming the author name (e.g., Allen D. Maloney --> A. D. M.), sorting the resulting list and eliminating duplicates (after manual checks).
- In addition, the last names of all authors were identified (e.g., F. David Fracchia --> Fracchia), sorted, and duplicate authors were merged again (after manual checks).
- Altogether 191 duplicate author names were identified. See duplicate author ids.
- There was one paper (acm673478) with no author.
- Citation Year (Publication Years)
- There were 8507 references extracted from the original dataset. After elimination of duplicates (5), there were 8502 references obtained. The publication year information for non-ACM publications that are cited by papers in the IV data set was retrieved for 8178 out of the total 8502 cited papers. The remaining 324 citations do not contain any year information (e.g., T.W. Rauber. Tooldiag. Universidade de Lisboa, Dept. of Electrical Engineering.).
- This info will be used to determine the total number of citations received each year (see Fig. 0.1) and to map the continuously evolving co-author space (Fig. 3.1.1).
Complete cleaned database: http://ella.slis.indiana.edu/~lviswana/iv04-contest.mdb
Relationship Among Various Components of Database

Summary Statistics for the InfoVis 2004 Dataset
- The dataset was analyzed using Microsoft Access and Microsoft Excel to get the summary statistics displayed in Figure 0.1. Raw data is available here. 614 papers were published between 1974 and 2004 (blue line).For each of the papers published in a given year, the number of references made in the papers to older publications was summed up (purple line). The total number of citation counts received by papers published in a given year was also obtained (brown line).
- There are 429 papers that have an abstract, 424 papers with keywords, and 340 papers that have both an abstract and keywords.
Descriptive Statistics for Info Vis 2004 Dataset
- Figure 0.1

- Analysis of Figure 0.1
- The plot shows that the number of Information Visualization papers is steadily increasing. The drop in the more recent years is most likely due to the fact that all papers are not available via the ACM library.
- As expected, older papers had more time to attract citations and the total number of references per paper increases as the number of produced papers increases.
- Papers published in 1995, 2000, 2002 show a significant increase in number of citations received as compared to citations received for papers published in 1999, 2001 or 1996. This might indicate the there were some papers published in 1999, 2000 or 2002 that were more significant milestones in Information Visualization research and formed the basis for further research.
Task 1: Static Overview of 10 Years of InfoVis
- Process:
- Knowledge domain visualization techniques [3] were applied to map the semantic space of the data set via citation analysis and co-citation analysis.
- The results of the citation analysis are visualized in Pajek [1] and are shown in Image 1.1. All papers that got cited at least 20 times (15 papers) and all the papers that cited those papers and themselves got cited by other papers, at least 7 times (44 papers), were selected. Elimination of duplicate entries resulted in 47 such papers, using which the below network was built. Each paper is represented by a circle. Node size denotes the number of received citations. Node color denotes year of publication. Ring color denotes the average citation year. It is computed using the formula:
∑ (number of times the paper is cited in a year * year in numerical form)
number of years in which the paper is cited
- Links represent direct citation links between papers.
- The results of the co-citation analysis in Pajek are shown in Image 1.2. For the paper co-citation analysis, only those papers that have been cited simultaneously by another paper, no less than 5 times, were considered. The similarity weight has been computed as the number of times these papers have received citations together.
- The references made by papers in the InfoVis dataset have been classified as those within the contest data set called IV core and others as ACM and non-ACM references. This is depicted in the diagram below to facilitate easier understanding of the insights provided thereafter.
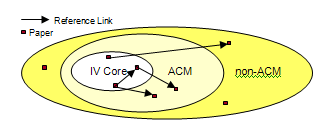
- Out of the 8502 references, 1970 references are to papers within the contest data set, called IV core. Only 1810 references are to other ACM publications and 4722 to non-ACM papers. These statistics suggest that the InfoVis community seems to be surprisingly disconnected from other research areas.
Paper-Citation Network
- Image 1.1:
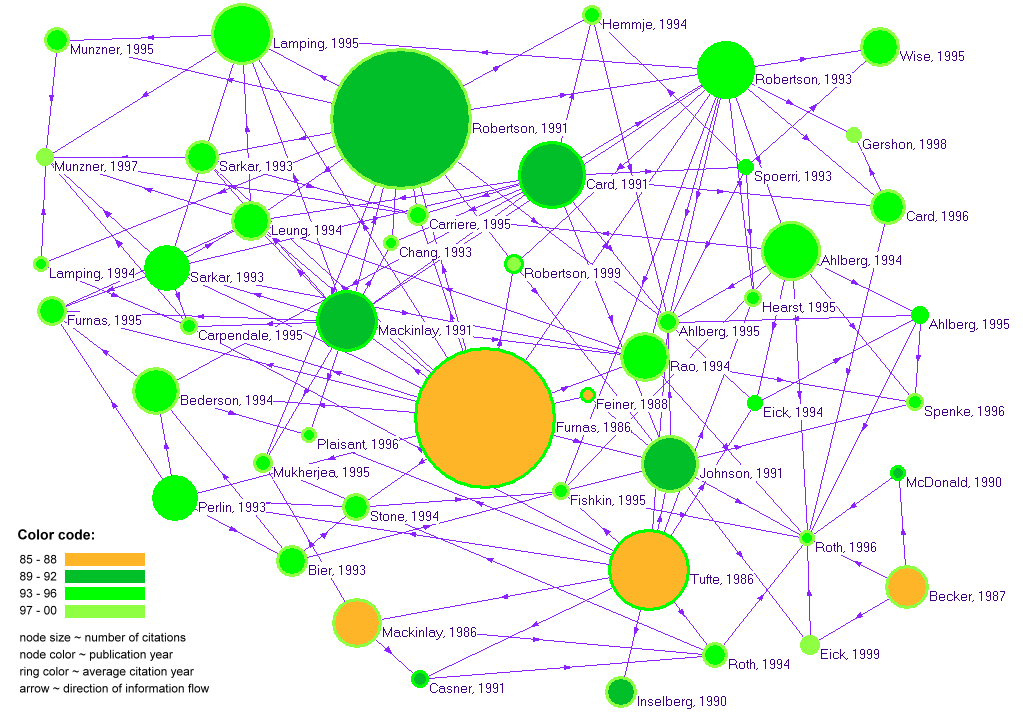
- Insight 1.1:
- Within IV core there are two papers that received 70 citations: Furnas's 1986 paper on Generalized fisheye views, and Robertson's 1991 paper on Cone trees: animated 3D visualizations of hierarchical information. Tufte's 1986 paper on The visual display of quantitative information was cited 40 times (see article_cited_count_withinset). It is interesting to note that papers within the IV core dataset have cited Bertin's 1983 book on Semiology of graphics: diagrams, networks and maps, the most number of times (14 times) amongst those in the non-ACM category. It is followed by Spence, R. and Apperley, M. Database navigation: An office environment for the professional, which was cited 9 times. The raw data for citation counts for articles, cited outside the core ACM dataset are at article_cited_count_outside_ACM. This reference is an example of one of the problems we encountered during data cleaning. This reference has an Id associated with it 9 out of the 12 times that it has been referred. We found the 3 additional citations that were lost on account of this problem in the dataset by manually scanning the same. But it would be difficult to do the same across all references in the dataset.
- Most nodes are a shade of green indicating that they are more recent, being published in between 1993 and 1995, and being cited in 1997 or beyond. This is also corroborated by the distribution of the number of papers published per year and number of citations per year in Figure 0.1.
- Similarly, the border color for most nodes is a yellowgreen, indicating that the average citation year is between 1997 and 2000.
- An interesting anomaly in this dataset that is evident from the visualization is that Robertson's 1999 paper The Document Lens, has been shown to be cited during earlier years, such as 1996, 1997, and 1995. This is impossible since a paper cannot be cited before it is published. This error in the latest version of the dataset has been beautifully captured in the visualization by the light yellowgreen color of the node (showing the year of publication) and the surrounding green color for the border(showing the average citation year). This shows that the quality of visualization and interpretation of information thereof depends largely on the quality of the dataset provided. A useful visualization capturing all the necessary information in the dataset can also be used to detect such errors in the data without having to peruse the raw data.
- Caption for Exhibit:
- The publication of the papers by Furnas 1986 and Robertson 1991 are the highlights of research in Information Visualization. These papers have the highest citation counts in the dataset, indicating that a large amount of research was spawned by these papers.
Paper Co-Citation Network
- Image 1.2:
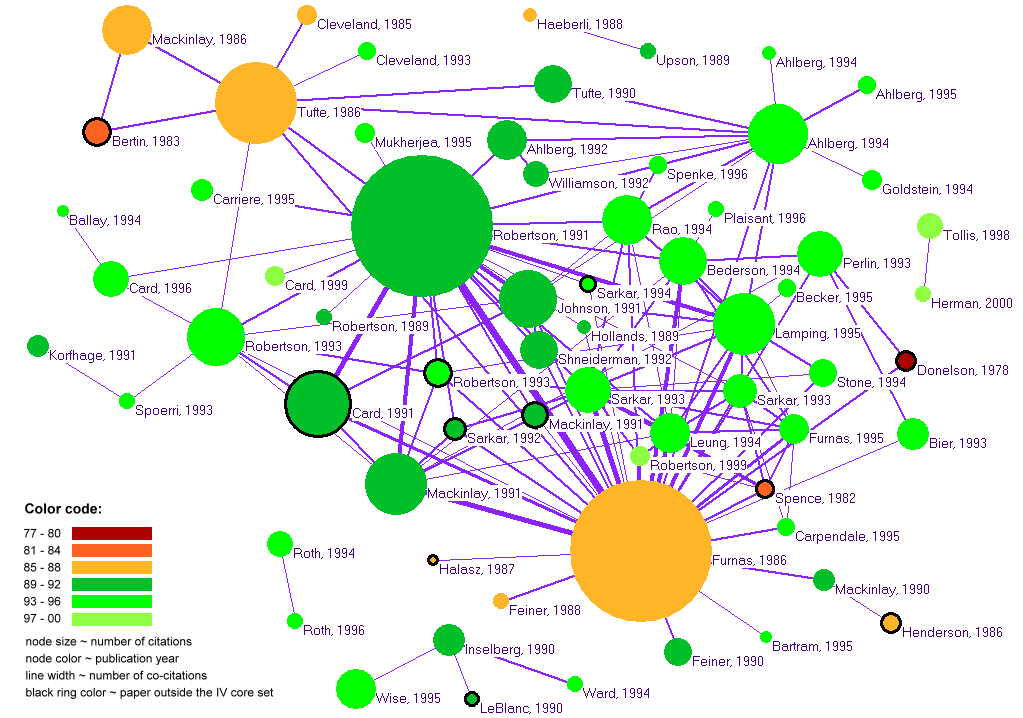
- A link to an interactive visualization of the paper co-citation network is also provided in SVG format. Check the co-citation counts to view the growth of the paper-co-citation network on the basis of similarity weights.
- Insight 1.2:
- The co-citation network places papers that are frequently cited together closer in space. A different picture emerges as compared to the citation network of individual papers in Image 1.1.The paper by Robertson, Mackinlay & Card, Cone trees: animated 3D visualization of hierarchical information appears to have among the highest number of co-citations (27) along with Furnas's Generalized fisheye views. It has been cited 19 times together with another of their publications, The information visualizer: the information workspace by Card, Robertson and Mackinlay.
- Not surprisingly, it is the papers co-authored by the trio of Robertson, Mackinlay and Card that have been cited together most often. These authors also happen to have the strongest degree of collaboration and co-authorship amongst themselves, as discussed below.
- Edward Tufte's 1986 paper on Visualization of quantitative information and Mackinlay's 1991 paper on Cone trees: animated 3D visualization of hierarchical information are not cited together very often (6), since both deal with visual representations of different kinds of information. This shows that the visualization reflects the underlying nature of co-citation amongst papers in an accurate manner, consistent with the nature of research presented in the papers.
- A noteworthy point is that most of the highly co-cited papers were authored by Robertson et al, during the early part of the nineties, when Infovis as a field of research was taking roots. This was also the time when this trio was working together in the field of Information Visualization at Xerox.
- Caption for Exhibit:
- Co-citation network of highly cited papers and the major papers they influenced.
Task 2: Characterize the major research areas and their evolution
- Process:
- A burst analysis of words in the InfoVis dataset was performed to study the evolution and progress of different research areas. We used the burst detection code available via http://iv.slis.indiana.edu and the results of the burst algorithm were plotted in Microsoft Excel.
- The keywords were organized in terms of years and a burst analysis was performed on these keywords in order to detect those words that experience a sudden increase or burst in their usage.
- The burst analysis was performed on words contained in
- Compound Terms in the Keywords of the dataset (.txt input file).
- Keywords and Title (.txt input file).
- Keywords, Title and Abstracts (.txt input file).
- The results of all three burst analyses (.xls file).
Burst Analysis of Compound Terms in the Keywords of the Dataset
- Image 2.1:

- Insight 2.1:
Word Burst Weight Burst Years Data visualization 3.7 1994-1995 Focus+context 4.29 1999-2002 Hierarchy 3.95 2000-2002 Human factors 3.42 1983-1994 Information Visualization 13.083 1998-present User Interface 3.457 1983-1991 - The burst analysis of compound keywords indicates that the focus of research from 1985-1991 was user interface. Human factors also has a high burst rate from 1974-1994.
- Around 1991 is the time when research in Information Visualization (in terms of papers published) also reached a peak. Taking 1991 as the year when Information Visualization as a field finally began to mature, the burst analysis indicates that the early years of research were focused on human factors pertaining to information visualization, such as user interfaces, etc.
- There were some seminal papers such as Generalized fisheye views and Cone trees: animated 3D visualizations of hierarchical information that were published during this period. Both of these papers deal with different methods of viewing information, with the latter being an improvement on the method described in the former.
- Given that these two papers are the most cited papers in the IV contest data set we can draw the conclusion that user interface and human factors formed the crux of Information Visualization research in the early years of the field.
- Subsequently, as the field matured, the focus shifted to information visualization as a field in itself. This is indicated by the corresponding burst in information visualization from 1998 onwards.
Burst Analysis of Compound Terms in the Keywords of the Dataset
- Image 2.2:
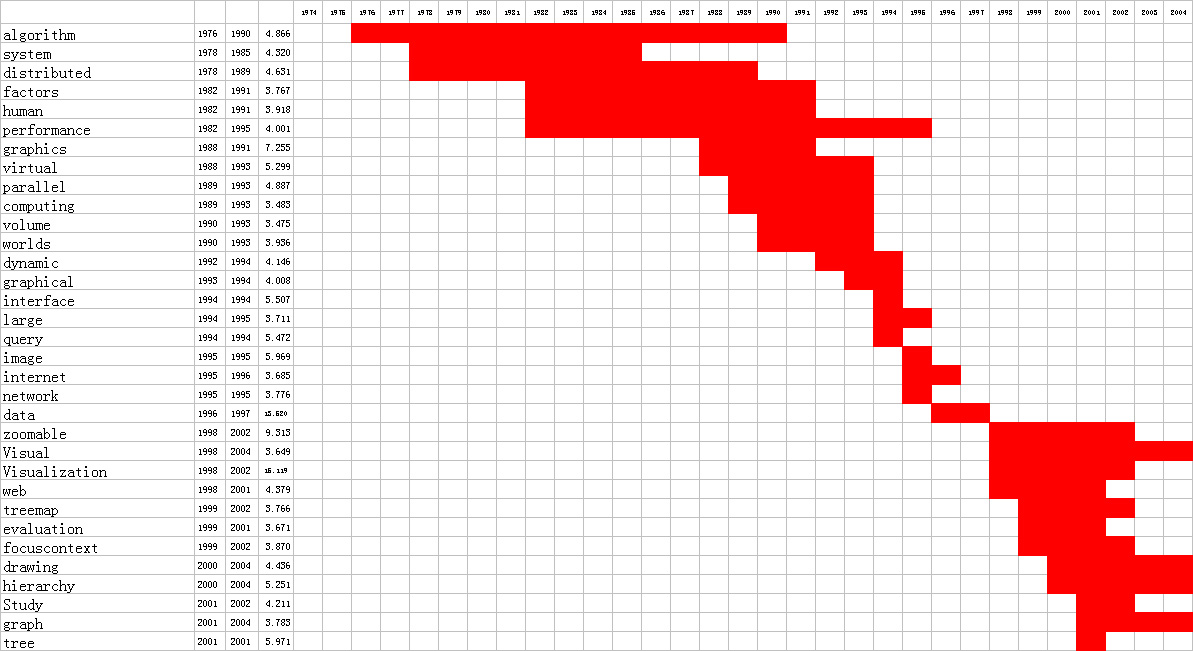
- Insight 2.2:
- The burst analysis for individual words in keywords, titles and abstracts shows that in the early years of InfoVis research, the focus was on algorithm, performance, graphics, human, etc indicating that the early research focused on creating useful and efficient algorithms, user-interface designs, etc.
- As the years progressed, the research focus shifted to integrating this research with the evolving Internet and parallelizing the algorithms, usage of network technologies and other similar efforts. This is indicated by the burst in the frequency of words such as parallel, internet, network, dynamic, query etc.
On the basis of the burst analysis we can conclude that the following were the main areas of research in Infovis
- User interface design
- Human factors in information visualization
- Data mining and visualization
- Techniques for information visualization and representation
- Web applications and network technologies in Infovis
Task 3: Identify the relationship among researchers in InfoVis
Task 3.1: Where does a particular author/researcher fit within the research areas defined in task 2?
- Process 3.1:
- We extracted the keywords from all the articles authored by George G. Robertson, Jock D. Mackinlay, Stuart K. Card, Steven F. Roth, John T. Stasko and Ben Shneiderman. The results for keyword counts for articles by
- Image 3.1:
Not applicable - Insight 3.1:
- The analysis of the keywords in papers authored by George G. Robertson show that his papers were primarily focused on user interface and 3D graphics. The phrase user interface occurred 3 times in keywords pertaining to his articles. There are many keywords such as interface metaphors, interactive animation, 3D user interface, etc in his articles. This reflects the research trend during the late eighties and early nineties of development of graphical user interface techniques. This was before the widespread use of graphical user interface systems. Early research in Infovis focused on evolving graphical user interface techniques for visualizing information. The keyword analysis of articles by Stuart K. Card and Jock D. Mackinlay also shows a similar trend. This is not surprising since these authors have collaborated extensively amongst themselves. This trio of authors has concentrated on development of user interfaces and dealt with the human-computer interaction aspects in information visualization.
- A keyword analysis of articles authored by Steven F. Roth show a high presence of words such as graphical user interface, interactive technique, intelligent interface and visual query. This shows that Steven F. Roth and his collaborators also concentrated on user interface design, albeit with a focus on making user interface more interactive and 3D oriented. During the early and mid-nineties, they were possibly extending the research carried out by the trio of Robertson, Card and Mackinlay.
- Research in user interface design formed the basis for further research in development of specific techniques and visual metaphors for information representation. A keyword analysis of articles authored by John T. Stasko shows the occurrence of circular/radial display, hierarchical visualization, and algorithm animation. This group was possibly focusing on developing specific visual metaphors and techniques for information visualization. This reflects the shift in research trends from development of basic user interface design during the late eighties to more advanced and intuitive information visualization during the mid-nineties.
- Similarly, the explosion of information available via the Internet during the mid-nineties led to a focus on data mining as a research area. This is reflected in the analysis of keywords of articles by Daniel A. Keim which shows a high presence of word such as large data sets, visualizing multidimensional data sets, visualizing multivariate data and data mining.
- An analysis of keywords in articles by Chi shows the presence of words such as world wide web, information ecologies and log file analysis, which indicates that Chi and his collaborators primarily focused on web applications and network technologies in Infovis.
- The keyword analysis of words in papers authored by Ben Shneiderman show an interesting trend. The phrase dynamic query occurs most often in his papers(8 times), apart from tree map, direct manipulation, algorithm and user interface . Ben Shneiderman is known to have extensively worked in the area of user interface design and developing tree map representations of information visualization. This fact is reflected in the statistics.
Task 3.2: What, if any, are the relationships between two or more or all researchers?
- Process 3.2:
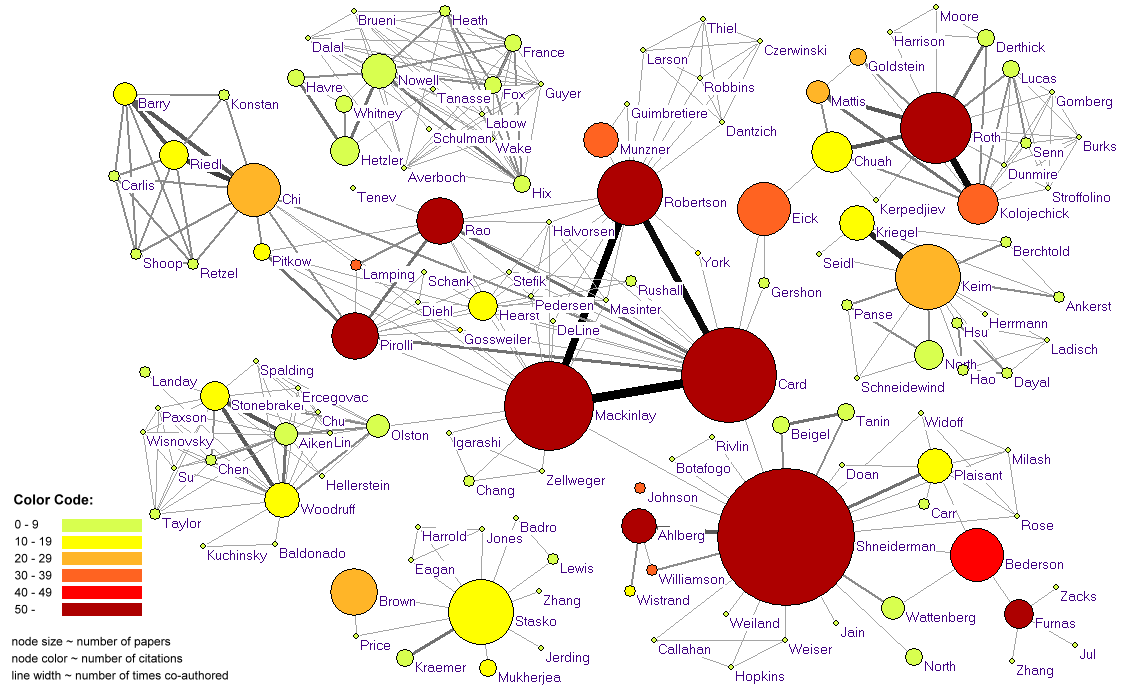
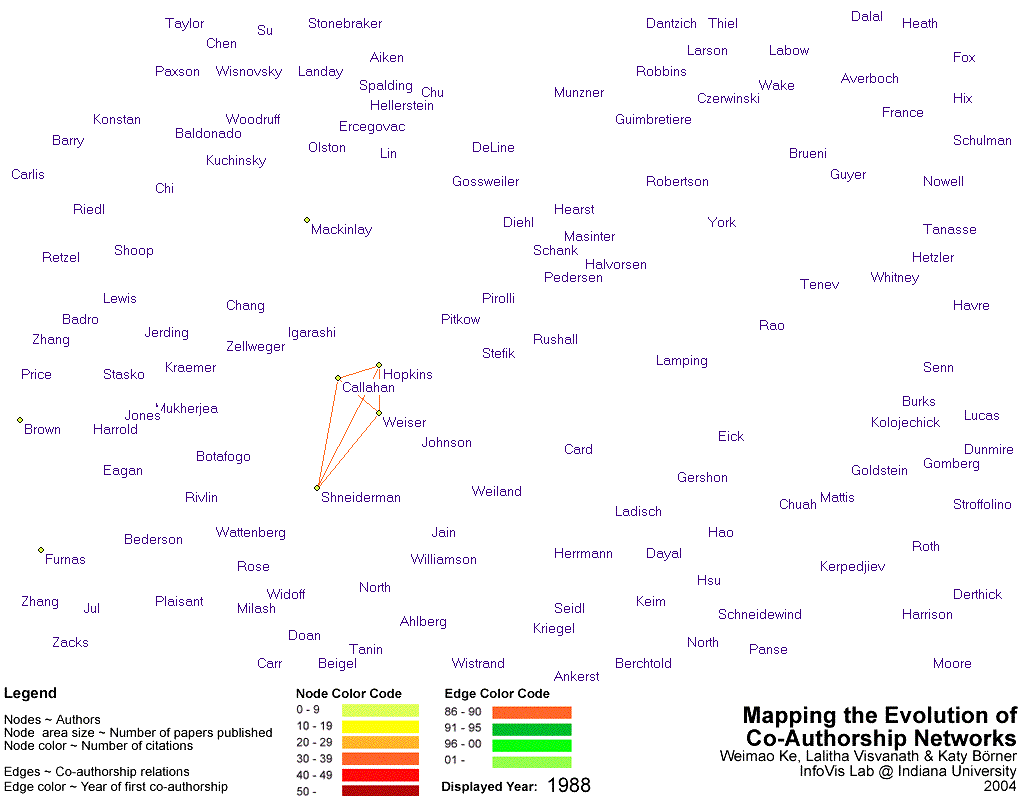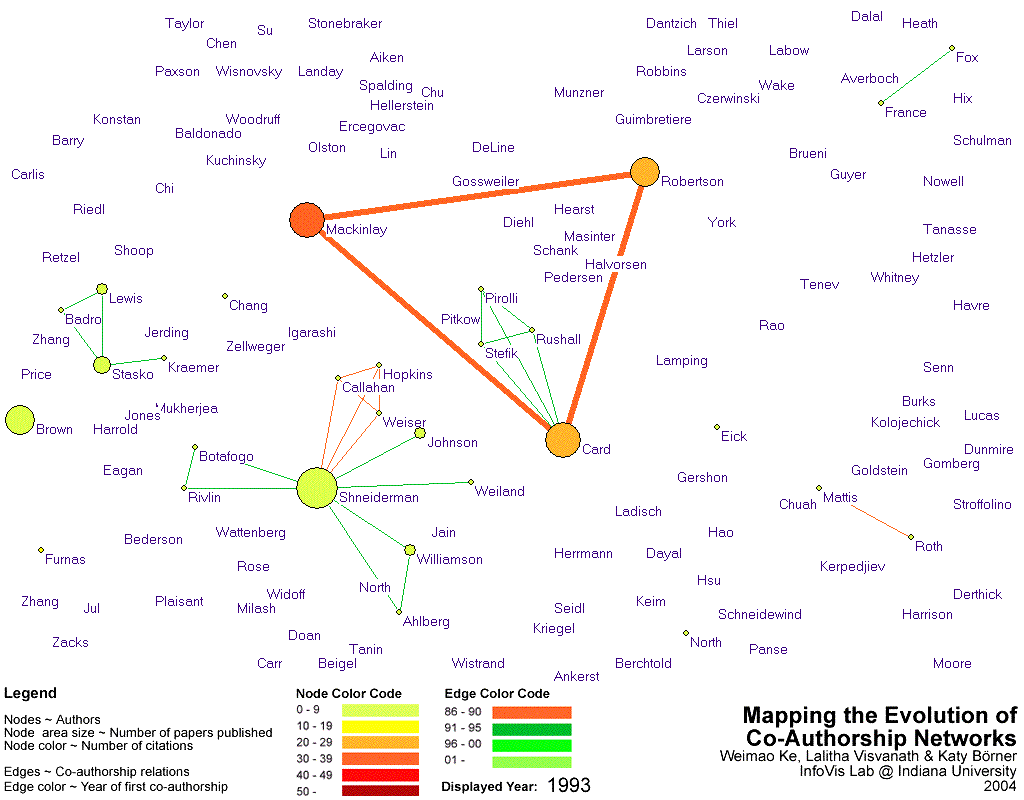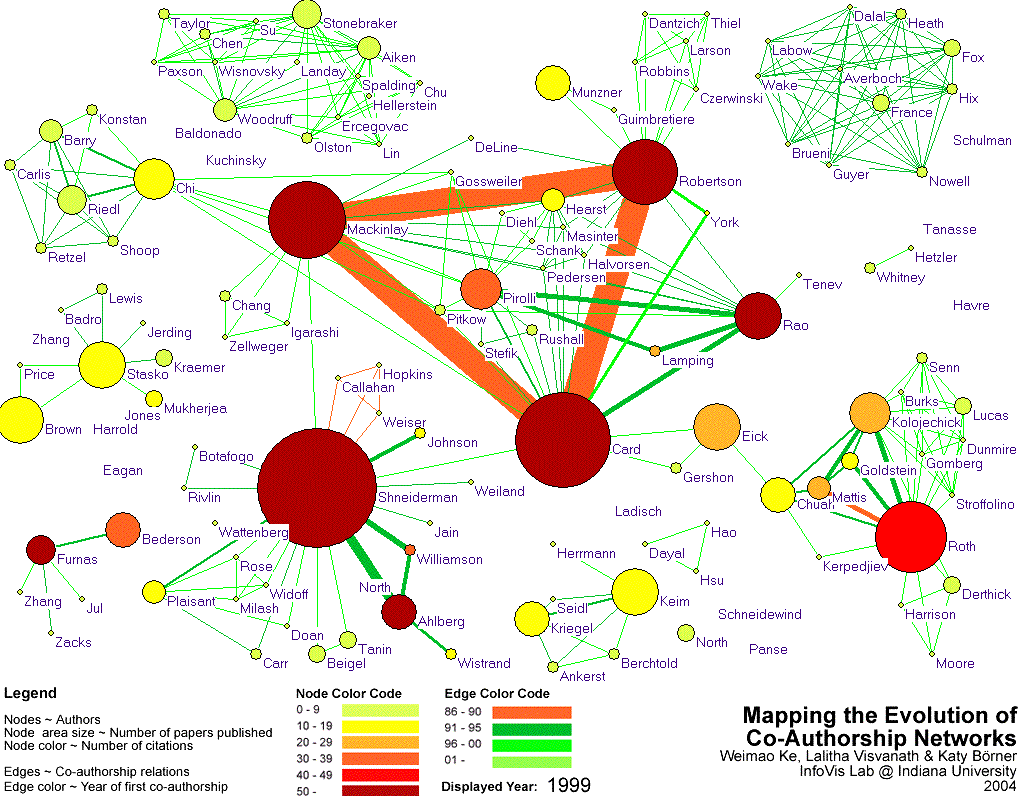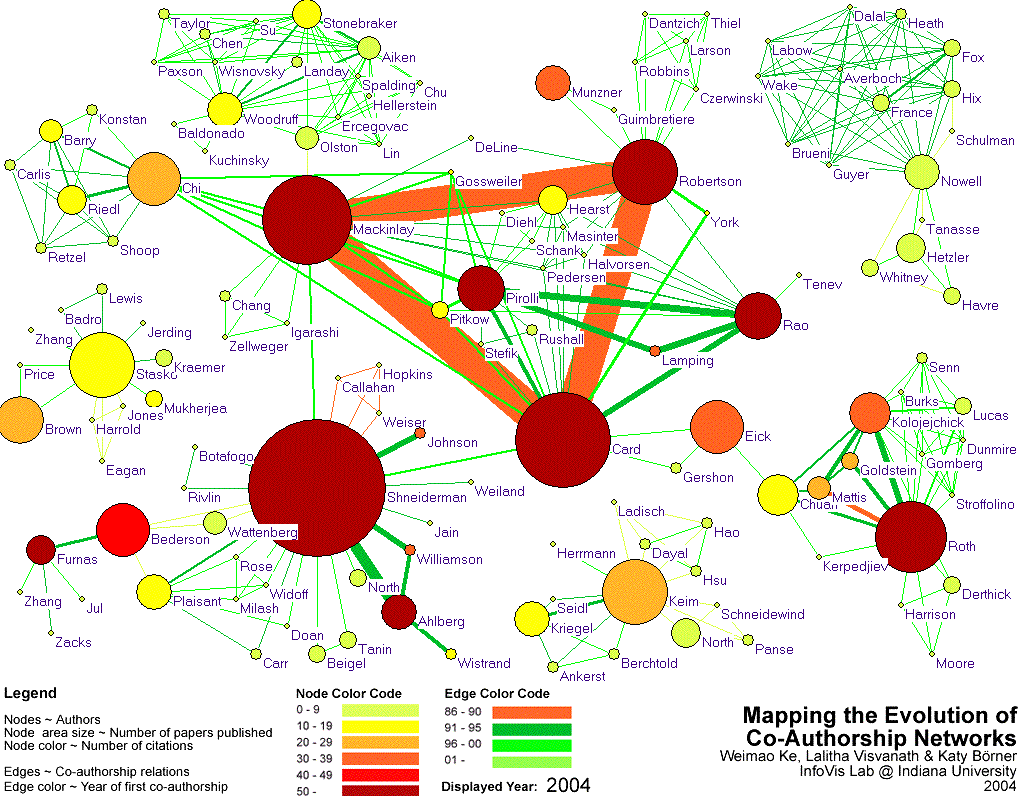
- Image 3.2 shows the frequency of co-authorship among authors, according to three criteria: all authors in IV core that published no less than 10 papers OR got cited no less than 50 times OR have no less than 20 times of co-authorship with other authors. 17 authors satisfied one or more of the three criteria. All of their co-authors are shown, as well as the resulting 138 author nodes. The node size corresponds to the number of papers published. Node color denotes the total number of received citations. Edge thickness indicates the number of times authors co-authored together.
- Image 3.2 shows the results of a time series analysis of the very same data set. While the node size was not changed, checking off the years leads to a progression of the interconnectivity structure of the co-author network.
- Image 3.2:
- A link to the interactive visualization of the co-author network has been provided in SVG format. Check the boxes showing number of times authors co-authored in order to watch the network grow.
- Insight 3.2:
- Scholars with more than 10 papers are Ben Shneiderman (23 papers), Stuart K. Card (16), Jock D. Mackinlay (15), Steven F. Roth (12), George Robertson (11), Daniel A. Keim (11) and John T. Stasko (11).
- Authors that received more than 100 citation links are Stuart K. Card (236), Jock D. Mackinlay (212), George G. Robertson (180) and Ben Shneiderman (173).
- The top four authors with the largest number of unique co-authors are Ben Shneiderman (23), Stuart K. Card (17), Jock D. Mackinlay (17) and George G. Robertson (16).
- In IV core, 93.3% of the authors have co-authored.
- The visualization reveals that although Ben Shneiderman authored the most papers, Stuart K.Card received the most citations for his work. One interesting finding is that Ben Shneiderman has a higher number of paper publications and citations to his credit than any of his co-authors. His strongest collaboration has been with Christopher Ahlberg and Catherine Plaisant. It is interesting that Ahlberg (73) is among the list of highly cited authors despite having a relatively smaller number of publications (6) to his credit. He could be among the newer set of scientists whose work in Infovis research has significant impact on the field.
- Nodes representing Ed H. Chi, Daniel Keim and Marc H. Brown are medium-sized and orange in color indicating that they could be cited more in the future.
- Diverse clusters of co-authors can be identified in the visualization. The trio of Stuart K. Card, Jock D. Mackinlay and George G. Robertson has co-authored a number of papers through their years at Xerox. These three authors have been the forerunners of research in Information Visualization. These authors are also the only group of people to have co-authored amongst themselves most often, indicating a very successful research trio. Apart from Stuart K. Card, who seems to have significant collaborations with both Peter Pirolli and Ramana Rao, both Jock D. Mackinlay and George G. Robertson do not seem to have any significant co-authors, despite the latter having the most number of co-authors.
- The visualization also indicates that most authors have not co-authored with the same author very often, except for this trio. This could be because of the evolving nature of the field and increasing number of scientists and researchers joining the field, thus giving rise to newer collaborations. This phenomenon could also explain the presence of most nodes in a light green color and being very small in size. The group consisting of nodes representing Lucy T. Nowell, Edward A. Fox, Dennis J. Brueni, and their co-authors is one such example. They possibly represent authors with fewer publications and fewer citations to their credit, on account of their relatively recent entry into the field.
- Steven F. Roth stands out as an author who has published a relatively large number of papers (12) and has received a sizeable number of citations (50) as well, but who has co-authored with authors with widely varying citation counts to their credit. His strongest collaboration has been with A. J. Kolojechick.
- As per the dataset Steven F. Roth has not co-authored with any author who has published more papers than him; the same is true of Ben Shneiderman.
- Another set of researchers who seem to have co-authored numerous times amongst themselves are John Riedl, Ed H. Chi, Joseph Konstan, Philip Barry and their co-authors.
- The presence of these distinct clusters could also be due to the different research foci and locations of these groups.
- Apart from the presence of few nodes of large size and dark color, representing Stuart K. Card, George G. Robertson, Jock D. Mackinlay, Ben Shneiderman, Steven F. Roth, Peter Pirolli, George W. Furnas, etc, most of the nodes are small and lighter in color. This could indicate that these and other similar nodes represent authors who have been involved in Information Visualization research since its earliest days, and are responsible for the large number of paper publications and citations that can be attributed to them.
- As expected George W. Furnas has very few co-authors in this visualization, probably due to the lesser number of scientists involved in Infovis research in its early days. The color and size of the node representing him shows that he is still widely cited.
- A link to a video (590 KB) depicting the frequency of collaborations among the authors is also provided.
- Image 3.3(a):

- A link to the interactive visualization depicting the history of co-author network has been provided in SVG format. Check years in chronological sequence to watch the growth of the co-author network over time.
- Image 3.3(b):
Time Slices of the Evolving Co-authorship Network
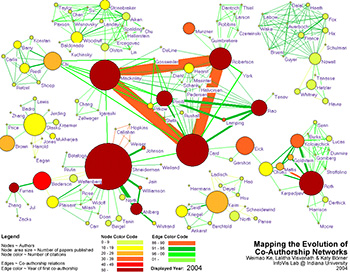
Click to animate - Insight 3.3:
- Image 3.3(a) shows the results of a time series analysis of the co-authorship network.
- A series of snapshots of the different stages of evolution of the co-authorship network has also been provided in Image 3.3(b)
- The link color indicates the year in which the authors began collaborating. The node color indicates the number of citations that they have received while the node size depicts the number of papers that they have published.
- Alternatively watch the provided video (1.5 MB).
- As the video depicts, Ben Shneiderman was amongst the earliest authors in the field of InfoVis. His earliest collaborations were with J. Callahan, M. Weiser and D. Hopkins, all of whom presumably did not focus on Infovis significantly, as indicated by their node size and color.
- As the network evolves, one can see the presence of Stuart K. Card, George G. Robertson, Steven F. Roth and Jock D. Mackinlay among the earliest collaborators, as expected.
- Subsequently, Daniel Keim, Peter Pirolli, Ramana Rao and Christopher Ahlberg are added.
- The presence of a sudden increase in the number of green colored links indicates that the number of collaborations and authors in Infovis grew significantly in the nineties. Sets of nodes worth noticing in this regard are those representing Lucy Nowell, Guillemo A. Averboch and Scott A. Guyer. The green color of the nodes and links between them could mean that this entire group of researchers began collaborating amongst themselves during the 1990s.
- Similarly Steven F. Roth seems to have begun collaborations with many different authors such as P. Lucas, Mei C. Chuah, Jeffery Senn, and C. C. Gomberg during the early part of the nineties.
- In the early years, one can see distinct clusters of authors, all of which are disconnected from one another. As the years go by, one can see an increasing number of connections among these isolated groups, suggesting greater collaborative work, and overlapping research interests among them.
Comments
We presented simple statistics, burst analysis results of keywords and semantic maps of major papers and authors based on the InfoVis Contest 2004 data set.
Given that the data set does not cover papers presented at the annual
InfoVis Conference in
Obviously, it would be very interesting to create a zoomable map of all authors, papers or topics. Ideally, the set of authors, papers or topics that is displayed could be interactively selected via sliders for attributes like number of received citations, number of papers per author etc. A map showing the interconnections among authors, their co-authors and their papers should be of great interest as well [4]. However we were limited in our efforts to display this information on account of the features of visualizing software such as Pajek [1].
Acknowledgments
Ketan K. Mane provided support in developing the visualizations for the citation networks and co-author networks. We appreciate the enormous effort by Jean-Daniel Fekete, Georges Grinstein and Catherine Plaisant and others in providing the context data set. This work is supported by a National Science Foundation CAREER Grant under IIS-0238261 and NSF grant DUE-0333623.
References
1. Batagelj, V. & A. Mrvar Pajek:
Program Package for Large Network Analysis.
2. Kleinberg, J.M. (2002). Bursty and hierarchical structure in streams. Proceedings of the 8th ACM SIGKDD Intl. Conf. on Knowledge Discovery and Data
Mining pp 91-101.
3. Börner, K., Chen, C., & Boyack, K. (2003). Visualizing knowledge
domains. In Blaise Cronin (Ed.), ARIST 37:Annual Review of Information
Science and Technology, (pp. 179-255),
4. Börner, K., Maru, J. & Goldstone, R. (2004). The simultaneous evolution of author and paper networks. PNAS, 101(Suppl_1):5266-5273.